
The phrase “AI on your phone” once sounded like sci-fi. But now, in 2025, mobile on-device machine learning capability is real, powerful, and a growing development choice. Developers weigh on device AI vs cloud AI, choosing where inference should happen, on the device or in the cloud.
Here in this article we will explore on-device AI integration benefits, capabilities, toolchains and techniques.
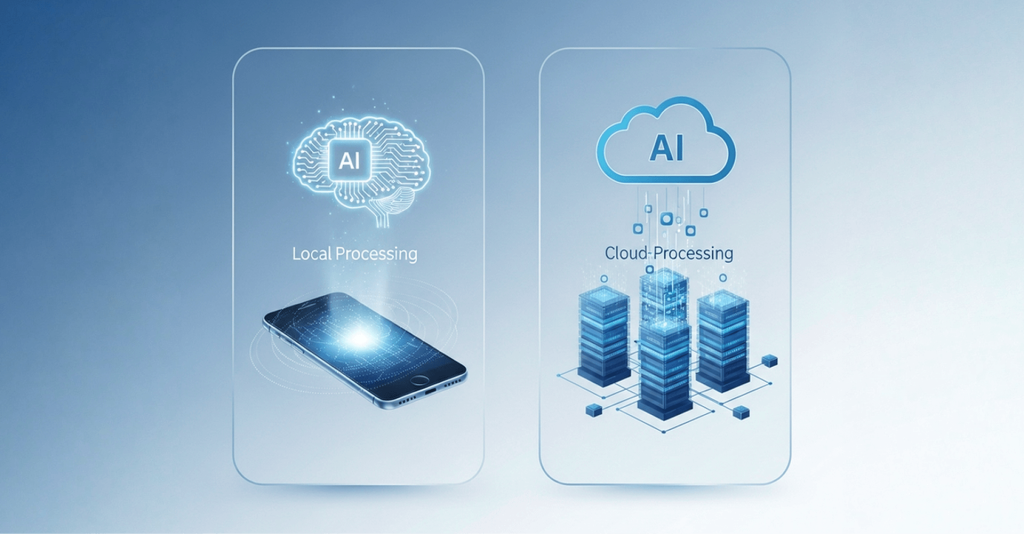
Why Do On-Device AI? Why Not Just Cloud?
Let’s start with the core trade-off: on device AI vs cloud AI. Both have merits; choosing one shapes your app’s user experience, architecture, and trust.
Benefits of On-Device AI
1. Latency & Responsiveness
When the model runs locally, there is no network roundtrip. That is huge for interactive features: image filters, speech recognition, AR effects. Users expect near-instant feedback.
2. Offline capabilities
In places with weak connectivity or air travel, you want features to keep working. On-device models enable edge AI on smartphone even when the network fails.
3. Privacy / Data minimization
If your logic runs locally, sensitive data never leaves the device. For apps that process health data, voice, face images, this is vital. This is the core promise of privacy preserving AI mobile app design.
4. Reduced cloud cost and scaling
Running AI inference in the cloud at scale incurs compute and bandwidth costs. On-device inference shifts that burden to the user’s hardware.
5. Better user experience
Users don’t need to wait, don’t need constant connectivity, and often won’t notice that the intelligence is happening right in their pocket.
Toolchains & Frameworks: The Engines for On-Device AI
To incorporate on-device AI capabilities, there are toolchains that optimize the otherwise performance-constrained hardware components. Here below we will shed light on some leading toolchains.
TensorFlow Lite Mobile Inference
This is a frequently used toolchain which is nothing but a lightweight and mobile-optimized version of TensorFlow.
- You need to convert a TensorFlow model to a TensorFlow Lite format.
- The TensorFlow Lite runtime is embedded in your mobile app and it works directly in the client interface.
- TensorFlow Lite supports GPU, NNAPI, and other hardware acceleration layers.
Core ML (Apple)
For iOS apps, Apple offers Core ML, optimized for Apple Silicon (iPhone, iPad). You can import models (e.g. in mlmodel format) and run inference tightly integrated with iOS frameworks.
Advantages of Core ML:
- Deep integration with iOS features (Vision, Core ML Tools, Metal).
- Often lower overhead, more efficient execution on Apple devices.
- Automatic model conversion support from many ML tools.
Other Toolchains
- ONNX Runtime Mobile – ONNX is an interoperable model format. ONNX Runtime supports mobile optimizations and hardware acceleration.
- PyTorch Mobile – Offers tools to compile PyTorch models for mobile inference.
- ML Kit / Firebase – Google’s ML Kit offers easier wrapper APIs for common tasks (OCR, translation, vision) using underlying TFLite.
- Edge computing runtimes – frameworks like Wasm-based inference, or microcontrollers using TensorFlow Lite Micro for extremely constrained devices.
Design Patterns & Architectural Strategies
Once the toolchain is chosen, architecture matters. Here are patterns that commonly appear in real apps with mobile on-device machine learning.
1. Feature-by-feature fallback
This is a hybrid pattern in which a feature prioritizes using the on-device model first. Only when it faces resource constraints, switches to a cloud call.
2. Progressive model loading
When the app first launches, start with a small model (fast to load). Later download a more accurate but heavier model in the background. This ensures first-run experience is fast, while giving you room to improve accuracy later.
3. Split logic
Separate core logic (preprocessing, I/O, control flow) from model inference. The inference part uses the heavy model; everything else remains in your typical app code. This separation helps in debugging and versioning.
4. Model swapping / fallback logic
This pattern maintains multiple model versions ranging from small, medium, and large. It chooses the right model at runtime based on device constraints, battery power, and available memory for the action.
5. Caching and results reuse
If inference results are stable (e.g. text recognition, translations), cache them. If input hasn’t changed, reuse results rather than re-running inference.
6. Deferred / background inference
This pattern is used for tasks that don’t need immediate response. This pattern runs the model inference in the background or when the device is not in use.
Model Compression Techniques for Mobile
A major challenge of doing AI on device is fitting models within tight resource constraints. Here’s where model compression techniques for mobile come in.
Quantization
Quantization is used to reduce the model weight such as stripping 32-bit floats to 8-bit 16-bit integers. This ensures faster performance while not compromising the accuracy of the output.
- Post-training quantization — easier but less optimal
- Quantization-aware training — trains the model with quantization in mind, preserving higher accuracy
Pruning & Sparsity
Remove weights or neurons that contribute little to predictions. The model becomes sparser and smaller.
Knowledge Distillation
Train a smaller “student” model to mimic a bigger “teacher” model. The student model is lighter and more efficient for mobile inference.
Weight sharing & clustering
Share similar weights across the model or cluster them to reduce storage footprint and memory usage
Model architecture redesign
Choose mobile-friendly architectures (MobileNet, EfficientNet, TinyML architectures) optimized for compactness and lower compute.
By combining these techniques, your model goes from “too big for mobile” to “usable on device.”
Privacy & Federated Learning on Mobile
One of the most compelling reasons to run AI on device is privacy. Users increasingly expect that their data, photos, voice, location, does not need to leave their device. That’s where privacy preserving AI mobile app design and federated learning on mobile come into play.
Privacy-first inference
Because inference runs locally, sensitive inputs never travel to servers. That is the heart of privacy preserving AI mobile app. Predictions are derived locally; only aggregated or anonymized insights (if needed) get shared.
Federated Learning on Mobile
Federated learning allows the models to automatically update across multiple devices without needing to expose raw device data.
Use cases:
- Keyboard prediction / next-word suggestions
- Health or fitness pattern detection
- Personalization (e.g. recommendation) without centralizing your history
But federated learning has challenges such as device heterogeneity, communication costs, update weighting, and dealing with noisy or biased data. Still, it’s a powerful pattern combining on device AI vs cloud AI in a privacy-conscious way.
Use Cases & Edge AI on Smartphone
Let’s explore edge AI on smartphone scenarios where running models locally enables new capabilities.
On-Device Speech Recognition Mobile
Transcription happens instantly without relying on the cloud. Apps like voice assistants, dictation, or captioning features can work offline. Real speech-to-text models are now deployed on-device. That’s classic AI inference on device.
AR Effects & Real-Time Filters
Snapchat-style filters, camera effects, background segmentation, all demand frame-by-frame inference. Doing that in the cloud introduces latency. On-device models make the experience interactive and live.
Smart Cameras & Vision
Object detection, motion tracking, face recognition, all localized. For instance, a security camera app can alert you based on local detection without streaming video constantly to servers.
Language & Translation Tools
Offline translation apps that do translation, transliteration, or phrase suggestions entirely locally. Users use these in remote areas with no cell signal.
Health & Sensor Data
Mobile apps analyze accelerometer, heart rate, or motion data to detect anomalies (falls, arrhythmias) locally in real time, critical for safety scenarios.
These are not pipe dreams. They are WebAssembly examples of edge AI that have already shipped in some apps.
FAQs
What is the difference between on device AI vs cloud AI?
On-device AI runs inference entirely on the user’s device, no data leaves the phone. Cloud AI sends data to servers for processing. On-device lowers latency and improves privacy; cloud enables heavier models and centralized updates.
What are model compression techniques for mobile?
You can use quantization, pruning, knowledge distillation, weight sharing, and choosing mobile-optimized architecture designs to shrink model size and improve speed.
Can on device speech recognition mobile apps match cloud accuracy?
They often come close. While cloud models may still win in extremely noisy conditions or for rare languages, many on-device speech models are now good enough for real-world use with strong privacy benefits.
How does federated learning on mobile work in practice?
Each user device trains the model locally using their data. It then shares only the model updates, not raw data, with a server for aggregation. The server sends back an improved global model, and the cycle continues, all while preserving each user’s privacy.
Final Thoughts
In 2025, edge AI on smartphone is no longer a niche experiment, it’s becoming a foundational capability. Teams that embrace mobile on-device machine learning will deliver faster experiences, greater privacy, and smoother user interactions.
BY ADMIN
October 16, 2025
